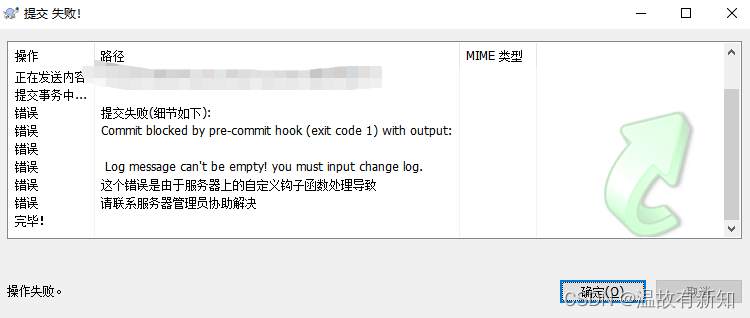
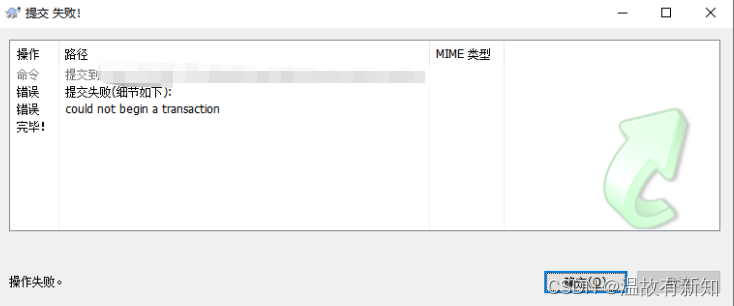
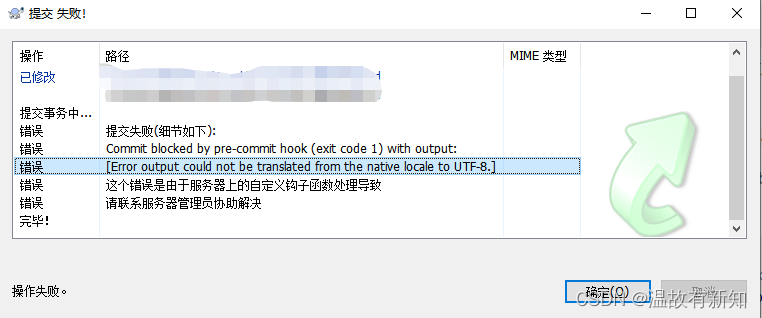
for rep in ${bakList[@]} do # 定义各个项目的初始版本号文件 svn_dir=$SVN_DIR/$rep svn_bak_dir=$SVN_BAK_DIR/full_log/$rep if [[ ! -d $svn_bak_dir ]] then mkdir -p $svn_bak_dir fi
#开始备份 svnadmin dump $svn_dir > $svn_bak_dir/${rep}_$DATE.dump if [ $? -eq 0 ]; then echo "backup success...." else echo "backup fail...." continue fi
cd $svn_bak_dir #清理过期备份 num=`expr $keep_log_num + 1` ls -t | tail -n +$num | xargs rm -rf done
# 设置网卡自启动,实际修改的是网卡配置文件 ONBOOT=yes nmcli con mod CON-NAME connection.autoconnect yes
# 修改IP地址是静态(manual)还是dhcp动态(auto) # 实际修改的是网卡配置文件BOOTPROTO,BOOTPROTO=none 表示静态;BOOTPROTO=dhcp 表示动态 nmcli con mod CON-NAME ipv4.method manual(static) | auto
# 修改IP配置及网关 nmcli con mod CON-NAME ipv4.addresses “10.10.10.10/2410.10.10.1”
# 修改默认网关 nmcli con mod CON-NAME ipv4.gateway 10.10.10.1
# 添加第二个IP地址 nmcli con mod CON-NAME +ipv4.addresses 10.10.10.10/16
# 删除第二个IP地址 nmcli con mod CON-NAME-ipv4.addresses 10.10.10.10/16
# 添加dns1 nmcli con mod CON-NAME ipv4.dns 114.114.114.114
# 添加dns2 nmcli con mod CON-NAME +ipv4.dns 8.8.8.8
# 一次添加多个dns nmcli con mod CON-NAME ipv4.dns 114.114.114.114,8.8.8.8,8.8.4.4
let ip = require('ip'); ip.address() // my ip address ip.isPrivate('127.0.0.1') // Check whether an IP is within a private IP address range. ip.isV4Format('127.0.0.1'); // Check whether an IP is a IPv4 address. ip.isV6Format('::ffff:127.0.0.1'); // Check whether an IP is a IPv6 address.
let net = require('net'); let client = net.Socket(); const host = '127.0.0.1'; client.connect(10033, host, () => { console.log('connect the server'); client.write('send first data'); });
client.on('data', data => { console.log('client data:', data); })
我:Why were carriage returns and line feeds created?
ChatGPT:Carriage returns and line feeds were created as a means of controlling how text was displayed on early computer systems and printers.
In the early days of computing, text was typically printed on teletype machines, which used a combination of mechanical and electrical systems to print characters on paper. These machines used a roll of paper that was fed through the machine, with characters being printed on the paper one at a time.
To control the position of the printing head, teletype machines used two separate control codes: a carriage return (CR) and a line feed (LF).
A carriage return (CR) code instructs the machine to move the printing head all the way to the left margin of the paper. This was necessary because the printing head would typically be positioned at the right side of the paper after printing a line of text, so a carriage return was necessary to reset the position of the head.
A line feed (LF) code instructs the machine to move the paper up by one line, so that the next line of text can be printed. This was necessary because the paper on a teletype machine was fed vertically through the machine, so moving the paper up by one line was necessary to print on the next line.
Today, carriage returns and line feeds are still used in some contexts, such as in programming languages or when working with text files in certain operating systems. However, the way they are used has evolved over time and varies depending on the specific context.
我:Why is the carriage return or line feed at the end of the text different in different operating systems?
ChatGPT:The reason why carriage return or line feed at the end of text is different in different operating systems is rooted in historical differences in how these operating systems handled text and line endings.
In Unix and Unix-like operating systems, such as Linux and macOS, a line feed (LF) character is used to mark the end of a line of text. This convention dates back to the early days of Unix, when it was developed as a text-based operating system. In Unix, files are stored as a sequence of lines, with each line terminated by a single LF character. This convention is also used in programming languages that were developed on Unix, such as C and its derivatives.
In contrast, in early versions of Microsoft Windows and MS-DOS, a carriage return (CR) followed by a line feed (LF) sequence is used to mark the end of a line of text. This convention goes back to the days of typewriters and teletype machines, which used both the CR and LF codes to signal the end of a line. When Microsoft developed its early operating systems, it inherited this convention.
The difference in line endings between Unix-like systems and Windows can cause issues when transferring files between systems. For example, if a text file created on a Windows machine is opened on a Unix system, the presence of the CR character may cause the lines to appear incorrectly. Similarly, if a text file created on a Unix system is opened on a Windows machine, the lack of the CR character may cause the lines to appear incorrectly.
To avoid these issues, many text editors and programming tools now have the ability to automatically convert line endings between Unix and Windows formats, or to handle both formats correctly.
我:Why is the end of the mac operating system a carriage return?
ChatGPT:Historically, Mac OS (now known as macOS) used a carriage return (CR) character to mark the end of a line of text. This convention dates back to the early days of the Macintosh computer, which was first introduced in 1984.
The Macintosh was designed to be a user-friendly computer that was accessible to non-technical users, and part of this design philosophy was reflected in the way it handled text. The original Macintosh operating system, known as System 1, used a simple, intuitive interface for editing text, which involved using the return key to create new lines of text.
To achieve this behavior, the Macintosh operating system used a single CR character to mark the end of each line of text. This was a departure from the convention used in other operating systems of the time, such as Unix and MS-DOS, which used a combination of a CR and a line feed (LF) character to mark the end of a line.
The use of a single CR character on the Macintosh made it easier for users to create and edit text, since they could simply press the return key to start a new line. However, this convention also made it difficult to exchange text files with other operating systems, which may expect a different line ending convention.
Today, macOS still uses a single CR character as the default line ending convention for text files created on the system. However, most modern text editors and programming tools are able to handle multiple line ending conventions, including the use of both CR and LF characters, to ensure compatibility with other operating systems.
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
// 获取当前的UTC时间 let now = newDate(); // 2022-02-09T07:35:37.335Z // 时间戳转为字符串格式 let now = newDate(0); // 1970-01-01T00:00:00.000Z let now = newDate(1644394635720); // 2022-02-09T08:17:15.720Z // 时间戳为负数则代表1970之前的时间 let now = newDate(-1644394635720); // 1917-11-22T15:42:44.280Z // 当前时间转化为时间戳(单位:ms) let now1 = newDate().getTime(); // 1644394635720 // 指定字符串格式的时间转换为时间戳 let now2 = newDate('2022-02-09T07:35:37.335Z').getTime(); // 1644392137335